由於各種的原因,現在不少人開始使用像ChatGPT 這樣的AI聊天機器人去嘗試進行醫療自我診斷。最近的一項調查顯示,大約六分之一的美國成年人已經至少每月使用聊天機器人尋求健康建議。
但牛津大學最近領導的一項研究表明,過於相信聊天機器人的輸出可能會有風險,部分原因是人們很難知道應該向聊天機器人提供哪些資訊才能獲得最佳的健康建議。
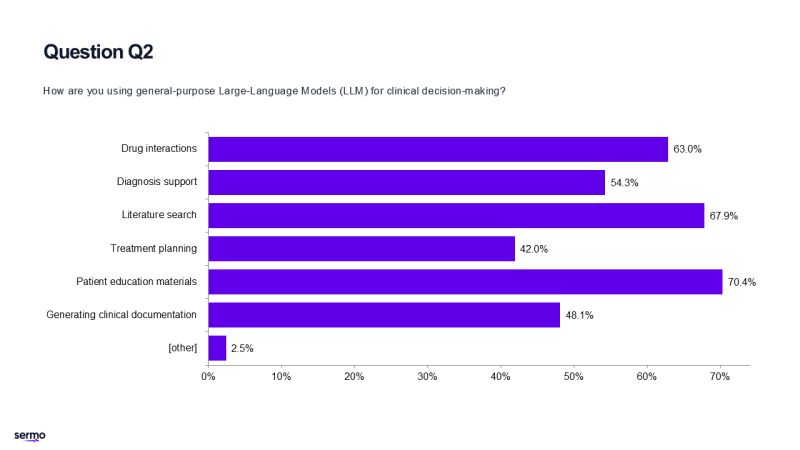
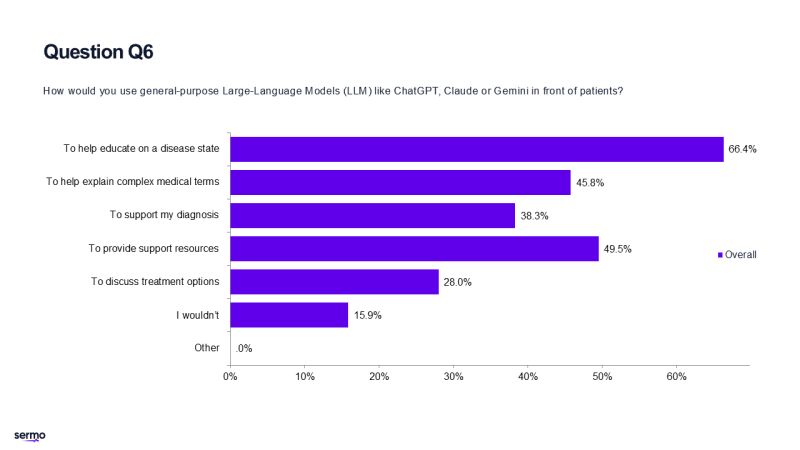
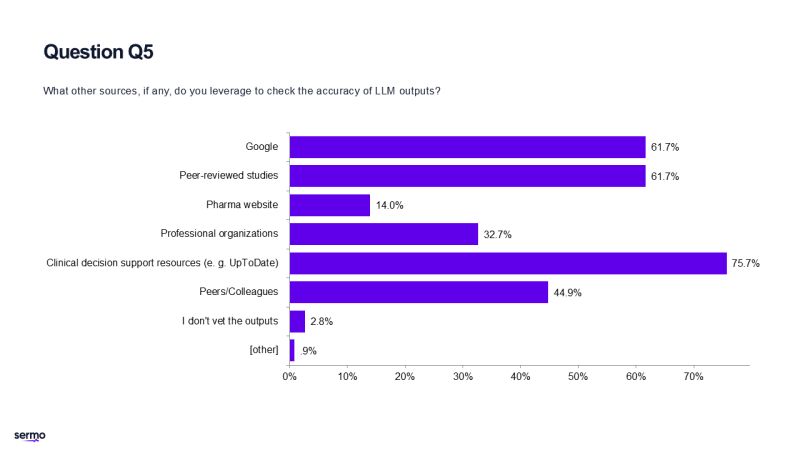
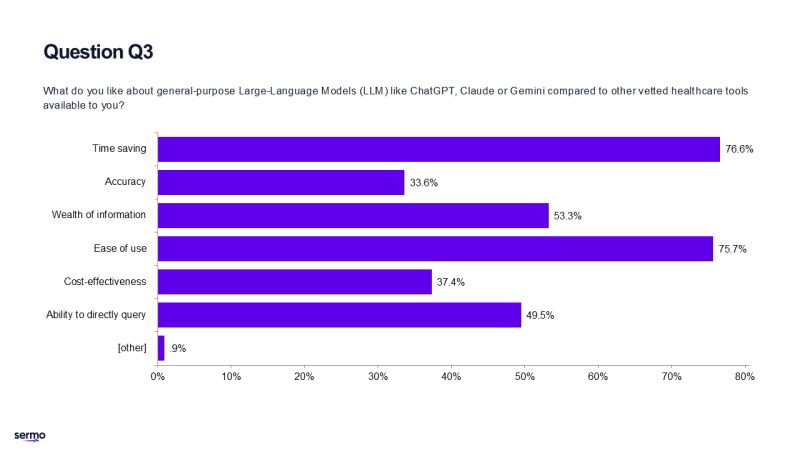
牛津網路研究所研究生院主任、該研究的合著者亞當馬赫迪表示這項研究正是揭示了雙向溝通的障礙。 「那些使用聊天機器人的人並沒有比那些依賴在線搜索或自身判斷等傳統方法的參與者做出更好的決策。」
這項研究中,作者在英國招募了約1300人,並向他們提供了一組由醫生編寫的醫療場景。參與者的任務是識別場景中的潛在健康狀況,並使用聊天機器人以及自己的方法來找出可能的行動方案(例如去看醫生或去醫院)。
參與者分別使用了ChatGPT、GPT-4o 以及Cohere 的Command R+ 和Meta 的Llama 3 。作者指出,AI聊天機器人不僅降低了參與者識別相關健康狀況的可能性,也使他們更容易低估已識別疾病的嚴重程度。
馬赫迪說,參與者在詢問聊天機器人時經常忽略關鍵細節,或收到難以解釋的答案。
同時他補充,AI聊天機器人給予的回應經常是好的和壞的建議並存。目前對AI聊天機器人的評估方法並沒有反映出與人類用戶交互的複雜性。
美國醫學會(American Medical Association) 建議醫生不要使用ChatGPT 等AI聊天機器人來輔助臨床決策,而包括OpenAI 在內的主要AI 公司也警告不要根據聊天機器人的輸出進行診斷。
馬赫迪說建議還是要依靠可靠的資訊來源來做出醫療保健決策。「目前對聊天機器人的評估方法並未反映出與人類用戶互動的複雜性。與新藥臨床試驗一樣,AI聊天機器人系統在醫學上的部署之前也應該在現實世界中進行測試。」








